
案件で機械学習の知識が必要になりましたのでDockerで環境を構築し、試してみようと思います。
以下の手順で進めます。
- Dockerでの環境構築
- Kaggleから訓練データ、テストデータをダウンロード
- データの整形
- 予測結果の出力
私は機械学習についての知識が皆無ですので間違っている箇所もあるかもしれません。。。
環境構築
環境はDockerで構築します。 Kaggle公式のDockerImageがあるらしいのでそちらを利用します。
docker-compose.yml
version: '3'
services:
app:
image: kaggle/python:latest
container_name: kaggle_container
volumes:
- ./src:/work
working_dir: /workkaggle/pythonでなくpythonのみのイメージでも良いのですがkaggle/pythonであればpandasなどのライブラリもインストール済みなのでオススメです。
$ docker-compose up -d
$ docker-compose exec app bash
> python -V
Python 3.6.6 :: Anaconda, Inc.これで環境構築は完了です。
Kaggle
Kaggleは機械学習、データサイエンスのコミュニティサイトです。
機械学習のための「訓練データ」と予測を分析する「テストデータ」をダウンロードすることができ、それを元に機械学習で結果を導き、Kaggleに提出するとScoreが表示されます。
今回は機械学習初心者向けである「タイタニック号の生存者予測」を試してみようと思います。
まず以下のページから訓練データである「train.csv」とテストデータである「test.csv」をダウンロードします。
https://www.kaggle.com/c/titanic/data#
それぞれ中身を確認してみます。
$ head train.csv
PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
1,0,3,"Braund, Mr. Owen Harris",male,22,1,0,A/5 21171,7.25,,S
2,1,1,"Cumings, Mrs. John Bradley (Florence Briggs Thayer)",female,38,1,0,PC 17599,71.2833,C85,C
3,1,3,"Heikkinen, Miss. Laina",female,26,0,0,STON/O2. 3101282,7.925,,S
4,1,1,"Futrelle, Mrs. Jacques Heath (Lily May Peel)",female,35,1,0,113803,53.1,C123,S
5,0,3,"Allen, Mr. William Henry",male,35,0,0,373450,8.05,,S
6,0,3,"Moran, Mr. James",male,,0,0,330877,8.4583,,Q
7,0,1,"McCarthy, Mr. Timothy J",male,54,0,0,17463,51.8625,E46,S
8,0,3,"Palsson, Master. Gosta Leonard",male,2,3,1,349909,21.075,,S
9,1,3,"Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg)",female,27,0,2,347742,11.1333,,S乗客ID, 生存可否, Passenger’s class, 名前, 性別, 年齢, 乗船した兄弟/配偶者の数, 乗船した親/子の数, チケット番号, 運賃, 船室番号, 乗船港となっています。
Passenger’s classは1, 2, 3の数値データで1がファーストクラスとなる船室クラスの数値のようです。
Embarkedは乗客が乗船した港で、C, Q, Sの3種類、それぞれCherbourg, Queenstown, Southamptonとなります。
$ head test.csv
PassengerId,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
892,3,"Kelly, Mr. James",male,34.5,0,0,330911,7.8292,,Q
893,3,"Wilkes, Mrs. James (Ellen Needs)",female,47,1,0,363272,7,,S
894,2,"Myles, Mr. Thomas Francis",male,62,0,0,240276,9.6875,,Q
895,3,"Wirz, Mr. Albert",male,27,0,0,315154,8.6625,,S
896,3,"Hirvonen, Mrs. Alexander (Helga E Lindqvist)",female,22,1,1,3101298,12.2875,,S
897,3,"Svensson, Mr. Johan Cervin",male,14,0,0,7538,9.225,,S
898,3,"Connolly, Miss. Kate",female,30,0,0,330972,7.6292,,Q
899,2,"Caldwell, Mr. Albert Francis",male,26,1,1,248738,29,,S
900,3,"Abrahim, Mrs. Joseph (Sophie Halaut Easu)",female,18,0,0,2657,7.2292,,Ctest.csvを確認してみるとSurvivedのデータがありません。
train.csvのデータで機械学習モデルを作成し、test.csvの乗客の生存可否(Survived)を求める。という課題のようです。
データの整形
欠損しているデータもあり、そのままでは使用できないので平均値などで埋めます。
そもそもどのくらい欠損しているのか見てみましょう。
import pandas as pd
train = pd.read_csv("./train.csv")
train_df = train.isnull().sum()
table = pd.concat([train_df], axis=1)
print(table)> python main.py
0
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2Age, Cabinが多く欠損していますがそれ以外のデータは問題なさそうです。
欠損値を埋める
Age(年齢)の欠損値を埋めます。
とりあえず中央値を使うように実装してみます。
train["Age"] = train["Age"].fillna(train["Age"].median())
train_df = train.isnull().sum()
table = pd.concat([train_df], axis=1)
print(table)medianで中央値を得ることができます。
> python main.py
0
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2これでAgeの欠損値は埋まりました。
CabinとEmbrakedも欠損していますが今回は使用しないのでこのままで進めます。
数値化とtest.csvデータの整形
次にデータの整形を行います。
今回使用する「決定木分析」では文字列を扱うことができませんので性別のデータを数値に変換します。
train['Sex'] = train['Sex'].map({'male': 0, 'female': 1}).astype(int)male(男性)を0、female(女性)を1に変換しました。
test.csvのデータも同様に整形します。
test = pd.read_csv("./test.csv")
# 中央値
test["Age"] = test["Age"].fillna(test["Age"].median())
test["Fare"] = test["Fare"].fillna(test["Fare"].median())
# 数値変換
test['Sex'] = test['Sex'].map({'male': 0, 'female': 1}).astype(int)test.csvについてはFareデータも一部欠損していましたので中央値で埋めています。
test["Fare"] = test["Fare"].fillna(test["Fare"].median())決定木分析
機械学習にはいくつかアルゴリズムがあるようなのですが、今回は決定木を使用してみます。
決定木は質問に対してYes, Noで分岐させる方法?らしいです。
まずは質問に使用する「説明変数」を用意します。
features = train[["Pclass", "Sex", "Age"]].values今回は船室クラス、性別、年齢で試してみます。
つまり、
- 船室クラスは1, 2, 3のどれか。
- 性別は0,1のどちらか。
- 年齢はいくつか。
という質問で分岐させて最終的な結果を導く。ということになります。
次に、予測したい変数「目的変数」を設定します。
生存可否を予測したいので「Survived」を選択します。
target = train["Survived"].valuesやっと決定木の作成です。
機械学習ライブラリである「scikit-learn」をimportして決定木を作成してみます。
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier()
tree = tree.fit(features, target)これで決定木モデルが作成できたので結果を求めてみます。
まずtest.csvデータの説明変数を用意して。
test_features = test[["Pclass", "Sex", "Age"]].values先ほど作成して決定木モデルで予測結果を求めます。
prediction = tree.predict(test_features)
print(prediction)> python main.py
[0 0 1 1 1 0 0 0 0 0 1 0 1 1 1 1 0 0 1 0 0 0 1 0 1 0 1 0 0 1 0 0 1 1 0 0 1
0 0 1 0 1 0 1 1 0 0 1 1 1 0 0 1 1 0 0 0 0 1 1 0 0 0 1 1 1 0 0 0 1 1 0 0 0
1 1 1 1 0 1 1 0 1 1 0 1 1 0 1 1 1 1 1 1 1 0 1 0 0 0 1 0 1 0 1 0 0 1 1 0 0
1 1 0 1 0 1 1 1 1 1 1 1 0 1 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 0 1 0 0 1 0 1 0
1 0 1 1 0 1 1 0 1 0 1 1 1 0 0 1 0 1 1 0 1 1 1 1 0 1 0 1 1 0 1 1 0 0 1 1 1
0 1 0 1 0 0 1 0 0 1 0 1 0 0 1 1 1 0 1 0 1 1 0 1 0 0 1 0 0 1 1 1 0 0 1 1 0
1 0 1 1 0 1 0 0 0 1 0 1 0 0 0 0 1 1 1 1 0 1 1 0 1 0 1 1 1 0 1 0 0 1 1 0 1
0 0 0 1 1 0 1 1 1 1 0 0 1 1 1 1 1 0 0 0 0 0 0 1 0 0 0 1 0 1 1 1 0 1 0 0 0
1 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 0 1 0 0 0 1 0 0 0 0 0 1 0 1 0 0 0 1 0 1
1 1 0 0 0 0 1 0 0 1 1 1 1 0 1 0 1 1 0 0 0 1 0 1 1 1 0 0 1 1 1 0 1 1 1 1 0
0 1 1 0 1 1 1 0 0 0 1 0 1 1 0 1 0 0 0 1 1 1 1 0 0 1 0 1 0 0 1 0 1 1 1 0 0
0 1 0 1 1 1 1 1 0 1 1]生存可否が0, 1で得られました。
Kaggleにアップロード
Kaggleにアップロードできるように結果をcsvファイルにします。
import numpy as np
PassengerId = np.array(test["PassengerId"]).astype(int)
result = pd.DataFrame(prediction, PassengerId, columns=["Survived"])
result.to_csv("result.csv", index_label=["PassengerId"])> python main.pyこれでresult.csvが作成されたのでKaggleにアップロードしてみます。
先ほどデータをダウンロードしたページの「Submit Predictions」をクリックしてアップロード画面に遷移します。

アップロード画面からresult.csvをアップロードし、完了まで待ちます。

完了したら結果を確認してみます。

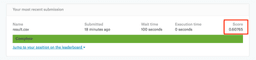
Scoreは0.6ですので正答率60%ということになります。

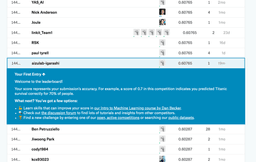
一応リーダーボードにも反映されました。
14441位です。。。
今回は船室クラス、性別、年齢のみで決定木を作成しましたがこれ以外の項目を含ませたり、欠損値を中央値でなく別の方法で埋めたり、そもそも決定木以外のアルゴリズムを使用したりすることでより正確な予測結果を得られるのだと思います。
奥が深いですね。。。
今回使用したソースコードは以下です。
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
train = pd.read_csv("./train.csv")
test = pd.read_csv("./test.csv")
# 欠損チェック
# train_df = train.isnull().sum()
# table = pd.concat([train_df], axis=1)
# print(table)
# 中央値
train["Age"] = train["Age"].fillna(train["Age"].median())
# 数値変換
train['Sex'] = train['Sex'].map({'male': 0, 'female': 1}).astype(int)
# 中央値
test["Age"] = test["Age"].fillna(test["Age"].median())
test["Fare"] = test["Fare"].fillna(test["Fare"].median())
# 数値変換
test['Sex'] = test['Sex'].map({'male': 0, 'female': 1}).astype(int)
# train.csvの目的変数と説明変数
target = train["Survived"].values
features = train[["Pclass", "Sex", "Age"]].values
# 決定木の作成
tree = DecisionTreeClassifier()
tree = tree.fit(features, target)
# test.csvの説明変数
test_features = test[["Pclass", "Sex", "Age"]].values
# 決定木モデルで予測結果を得る
prediction = tree.predict(test_features)
# csvファイル出力
PassengerId = np.array(test["PassengerId"]).astype(int)
result = pd.DataFrame(prediction, PassengerId, columns=["Survived"])
result.to_csv("result.csv", index_label=["PassengerId"])まとめ
全く無知の状態で調べながらでしたがスムーズに結果を得ることができました。
Dockerで環境も簡単に用意できますし、Pythonライブラリのおかげで手軽に実装、実行することができますので興味のある方は試してみてはいかがでしょうか。









